The Agile Manifesto establishes 12 principles for Agile software development. Most software that has a dependency on another software inherits its Agile features—and in this article, we will explore what makes Apache Kafka suitable for Agile software development.
The Agile Manifesto establishes 12 principles for Agile software development. These Agile principles include simplicity, individuals and interactions, customer collaboration, responding to change, early and continuous delivery of valuable software, the ability to welcome changing requirements, and the ability to deliver working software frequently. Most software that has a dependency on another software inherits its Agile features—and in this article, we will explore what makes Apache Kafka suitable for Agile software development.
Simplicity
Apache Kafka is based on a simple data flow model for messaging. A Kafka Producer client application produces messages and writes them to a durable store called a Topic, while a Kafka Consumer client application reads or consumes the messages from the Topic. The message flow is illustrated in Figure 1.
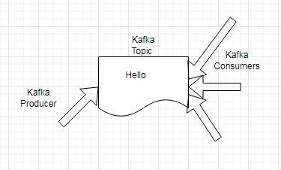
Figure 1. Apache Kafka Message flow
Apache Kafka is based on a simple model based on events. Each message and record is an event. Events are pushed to a topic by a producer and pulled from a topic by a consumer. Each topic can have one or more producers and one or more consumers associated with it. Several other simplicity-related features are built into Kafka Streams:
- The data processing occurs within the Kafka cluster itself without the need for a separate cluster
- Supports commonly used programming languages: Java and Scala
- Supports commonly used OS: Windows, Linux, and Mac
- Can be deployed on a local machine, on the cloud, on VMs, and within containers
- Processes each record once only, and one record at a time
- Messages are stored on a disk’s file system
Individuals and Interactions and Customer Collaboration
Agile principles emphasize individuals and interactions, as well as customer collaboration. Apache Kafka provides several mailing lists for developers and end-users to promote individual interactions and customer collaboration.
Responding to Change
Responding to change, which usually occurs in real-time within a web-hosted application that is being used by multiple users, is important for Agile development. Apache Kafka Streams is a client library that can be used to develop real-time applications and microservices that are based on event streaming. Streaming analytics can be performed without much latency.
Apache Kafka is a highly distributed and scalable platform. Kafka is run as a cluster on servers that may span multiple regions making it highly available and fault-tolerant. Servers are specialized; the ones that store data are called brokers. Kafka clients are used for developing distributed applications to access Kafka servers as well as read, write, and process streams of data.
Early and Continuous Delivery of Valuable Software
Apache Kafka can be used in data pipelines that make use of continuous integration/continuous delivery to deliver valuable software continuously. A streaming data pipeline can collect data from one or more data sources, and stream the data to data consumers, perhaps for data analytics.
Welcome Changing Requirements
Apache Kafka is a very versatile platform that can be used for a multitude of use cases including the following:
- Messaging
- Tracking website activity
- Collecting metrics data
- Aggregating logs
- Processing data in streaming pipelines
- Event sourcing for recording a time-ordered sequence of events
Deliver Working Software Frequently
Working software has to be based on other software that is reliable. Apache Kafka is a distributed, highly available, fault-tolerant platform.
Failure handling is built into Kafka Streams in several ways:
- Kafka stores stream data into topics which are partitioned and replicated. So, even if an application fails the stream data is still available.
- Within a Kafka cluster, if a task running on one machine fails, Kafka automatically restarts the task on an available machine in the cluster.
- Local state stores are failure-tolerant. A replicated changelog Kafka topic that is partitioned is kept to store state updates. Corresponding changelog topics are replayed when a failed task is restarted on a new machine. Failure handling is transparent to end users. The time delay in restarting a failed task can be reduced by configuring standby replicas.
Well-Integrated
Apache Kafka is well-integrated with other data processing frameworks, which is important because a data processing application typically makes use of multiple frameworks. Some examples of integration are discussed below.
Apache Flume
Apache Flume is a distributed framework for collecting, aggregating, and storing logs of data from multiple data sources. Apache Kafka is supported as a channel in Apache Flume. The Flafka project was developed to support Flume-Kafka integration. Flume sources can be used to write to Kafka, while Flume sinks to read from Kafka.
Apache Sqoop
Apache Sqoop is a framework for bulk transferring data between Apache Hadoop and different types of structured data stores. The Kafka connector for Apache Sqoop can be used to transfer bulk data from Apache Hadoop to an Apache Kafka topic.
Apache Beam
Apache Beam is a framework used for developing batch and streaming parallel data processing pipelines. The apache_beam.io.kafka module provided by Apache Beam can be used to read from Kafka and write to Kafka.
Apache Flink
Apache Flink is a framework used to perform stateful computations over data streams. Flink provides an Apache Kafka connector for reading data from a Kafka topic and writing data to a Kafka topic.
Other External Systems
The KafkaCollect API supports integration with other external systems including relational and NoSQL databases. The MongoDB Connector for Apache Kafka can be used to persist data to a Kafka topic from MongoDB, and persist data to MongoDB from a Kafka topic. The MongoDB Connector can be configured as a Source or a Sink. Kafka connectors are also available for other databases that include Apache Cassandra, Couchbase, MySQL, and PostgreSQL.
Managed Service
Apache Kafka is available as a managed service on AWS, called Amazon Managed Streaming for Apache Kafka. A managed service provides several benefits including scalability, high availability, production-ready development and deployment, and integration with other AWS services for logging and monitoring. The managed service can be used with applications developed with the open-source Apache Kafka.
With such an Agile framework, several other open-source projects are based on Apache Kafka including Kafka Mesos Framework, Spring for Apache Kafka, and The Apache Kafka C/C++ client library librdkafka.

User Comments
nice post
I think this article is a valuable resource for learning more about the Agile features of Apache Kafka. I appreciate the author's clear and concise explanation of the concepts and examples. Do you have any other articles or books on this topic?